Merge and Remove duplicated data
This page shows how to check the timestamp of a new dataset, insert this data in the correct time series location in master file, and remove duplicated data.
Function of data insertion
# ----- Read TWO (new entry and master) CSV files -----
df1 = pd.read_csv(indir1+filename1 \
, delimiter = ',', na_values = ['NAN','"NAN"'], skiprows=[0,2,3], header=0, low_memory=False, index_col=0)
dfm = pd.read_csv(indirm+filenamem \
, delimiter = ',', na_values = ['NAN','"NAN"'], skiprows=[0,2,3], header=0, low_memory=False, index_col=0)
#--- add additional information of headers ----
if stid1 == stidm:
time1 =pd.Series(pd.to_datetime(df1.index))
timem =pd.Series(pd.to_datetime(dfm.index))
newdf = insert_dat(dfm,df1,timem,time1,func)
timestamp = pd.Series(newdf.index)
newdf.index = timestamp
newdf['RECORD'] = range(0,newdf.shape[0])
‘df1’ is the data of the new dataset, and ‘dfm’ is the data of the master file at each station.
Data insertion is performed when the station IDs (stid1, stidm) of the two files are the same.
Subroutine of data insertion
This subroutine defiles the timestamps of the new dataset and master file and determines wherein the master file the new data will be inserted.
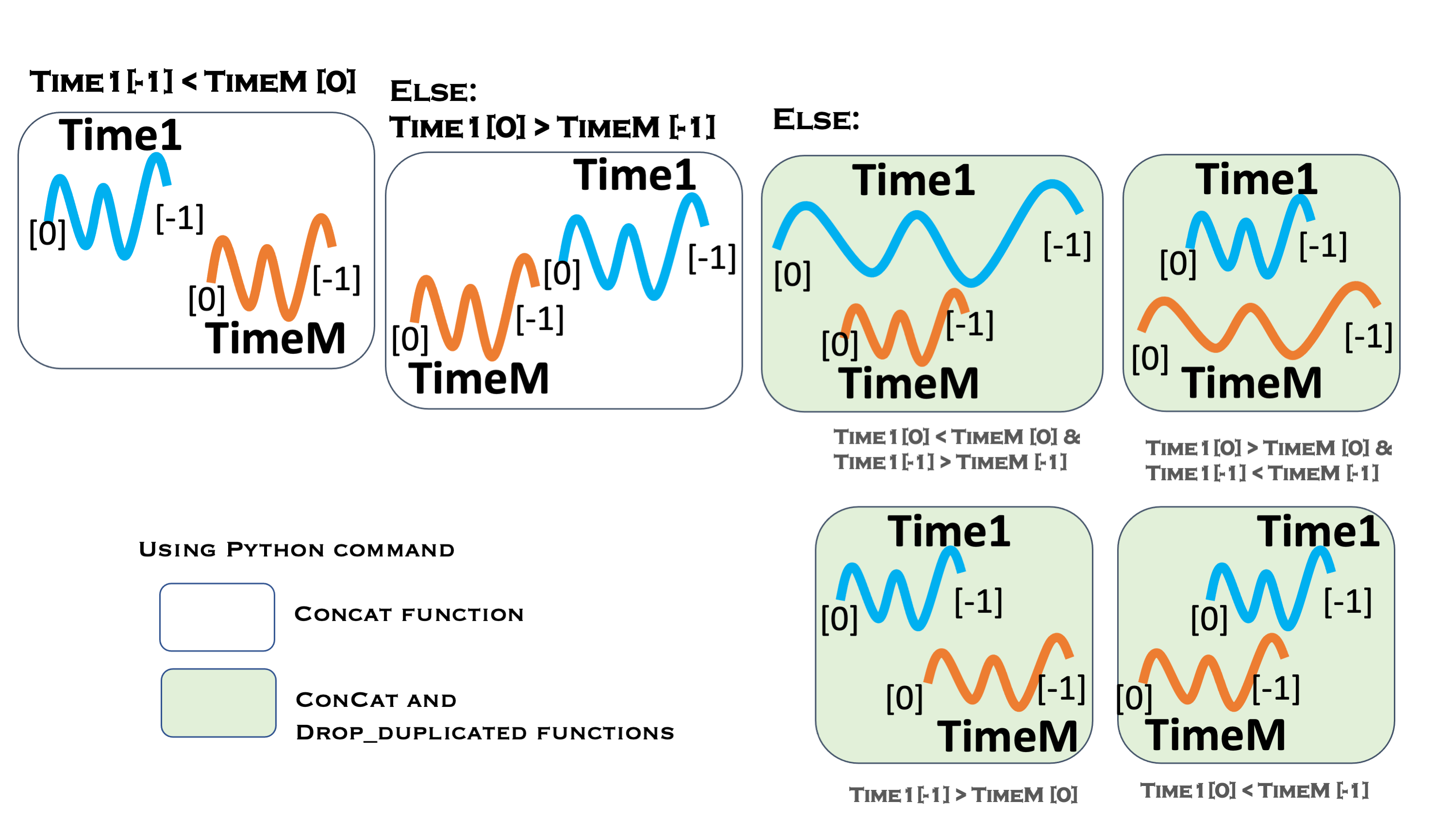
def insert_dat(dfm,df1,timem,time1,func):
if time1.iloc[-1] <= timem.iloc[0]:
print("New entry is old than the masters: ",timem[0],'-',timem.iloc[-1],' ',time1.iloc[0],', ',time1.iloc[-1])
newdf = pd.concat([df1,dfm],axis=0)
else:
if time1.iloc[0] > timem.iloc[-1]:
print("new entry is new than the masters: ",timem[0],'-',timem.iloc[-1],' ',time1.iloc[0],', ',time1.iloc[-1])
newdf = pd.concat([dfm,df1],axis=0)
else:
print("some new entry overlap with the masters:",timem[0],'-',timem.iloc[-1],' ',time1.iloc[0],', ',time1.iloc[-1])
df1['label'] = 0
dfm['label'] = 1
newdf0 = pd.concat([df1,dfm], ignore_index=False)
newdf0['TIME2']=newdf0.index
# sort data in chronological data
newdf0.sort_values(by = ['TIME2','label'],inplace=True)
# drop the data to be duplicated, leave the 'func'th data of the duplicated data
newdf = newdf0.drop_duplicates(subset=['TIME2'],keep=func)
newdf = newdf.drop(['TIME2'],axis=1)
newdf = newdf.drop(['label'],axis=1)
return newdf
Sample program for inserting (time series) dataset into a master file
This program gets a filename under multiple directories (station names) and reads the data in one file in each directory.
Source file: merge_2files.v02.py